Explainability and Utterances Annotation
Explainability is a language evaluation tool that addresses intent recognition and answers the question “Why should bot authors trust DRUID machine learning model?” This tool helps bot authors get insights into the machine-learning model to easily understand the reasons behind bot behavior, figure out when they shouldn’t trust the model even if the accuracy is high and improve the model to make it trustworthy.
DRUID Explainability provides explanation on why the NLP model associated an utterance to a specific flow and allows bot authors further fine-tuning the NLP model by annotating utterances (creating a more trustworthy machine learning model).
How it works
DRUID Explainability uses the Local Interpretable Model-Agnostic Explanations (LIME) algorithm that explains the predictions of word embedding classifier in an interpretable and faithful manner.
Word Embedding is a method of extracting words out of text and input them into a machine-learning model to work with text data.
The LIME algorithm takes the training phrase, extracts each word within the phrase and approximates the NLP model locally in the neighborhood of the prediction being explained; it checks how the extracted word matches against the NLP model (which is considered a black box), puts the word back, checks again how it matches. If there are differences between the two matching tries, the extracted word contributes positively or negatively to the flow association.
Then the algorithm produces visual explanations that are simple for bot authors to understand.
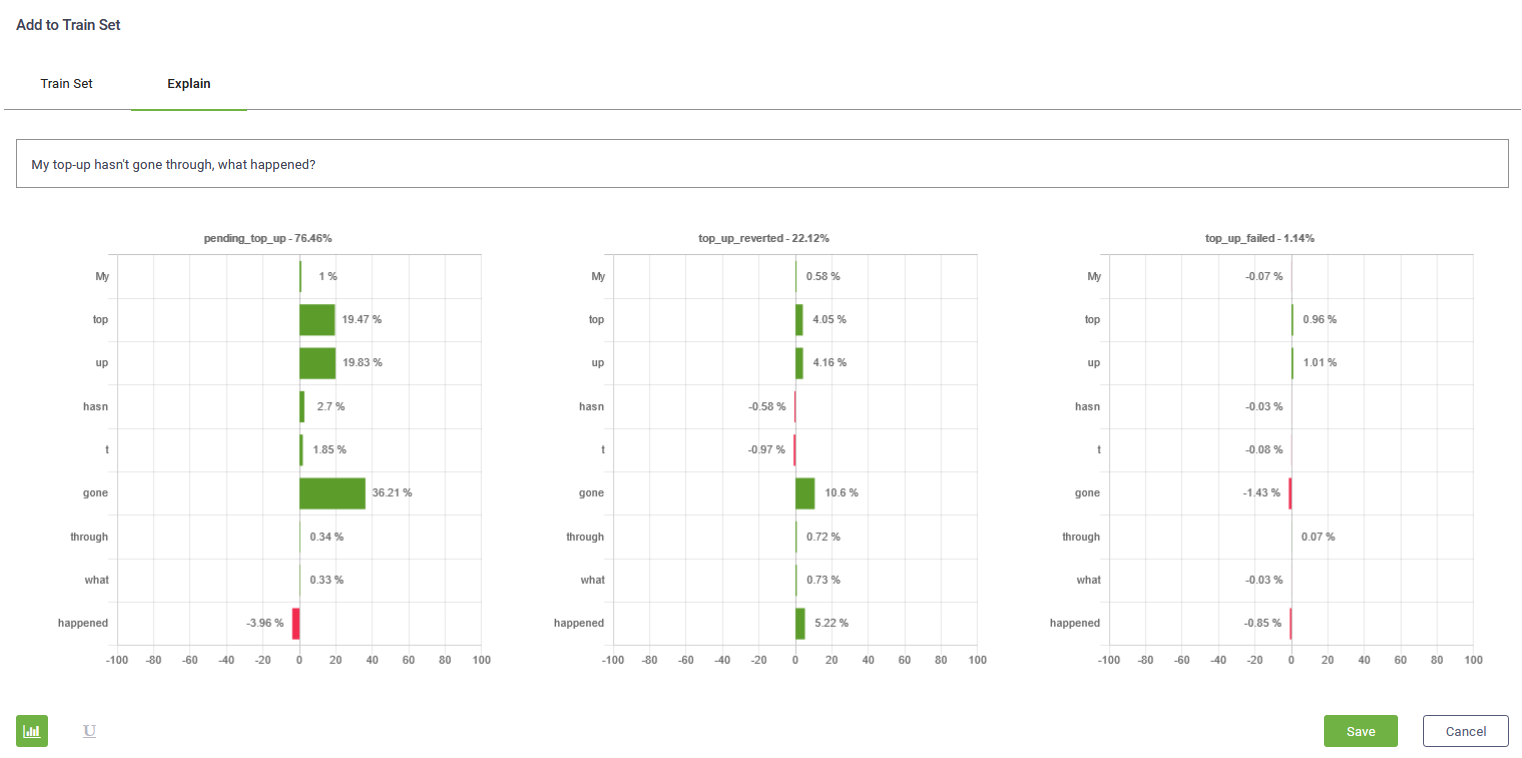
Explain utterance matching flows
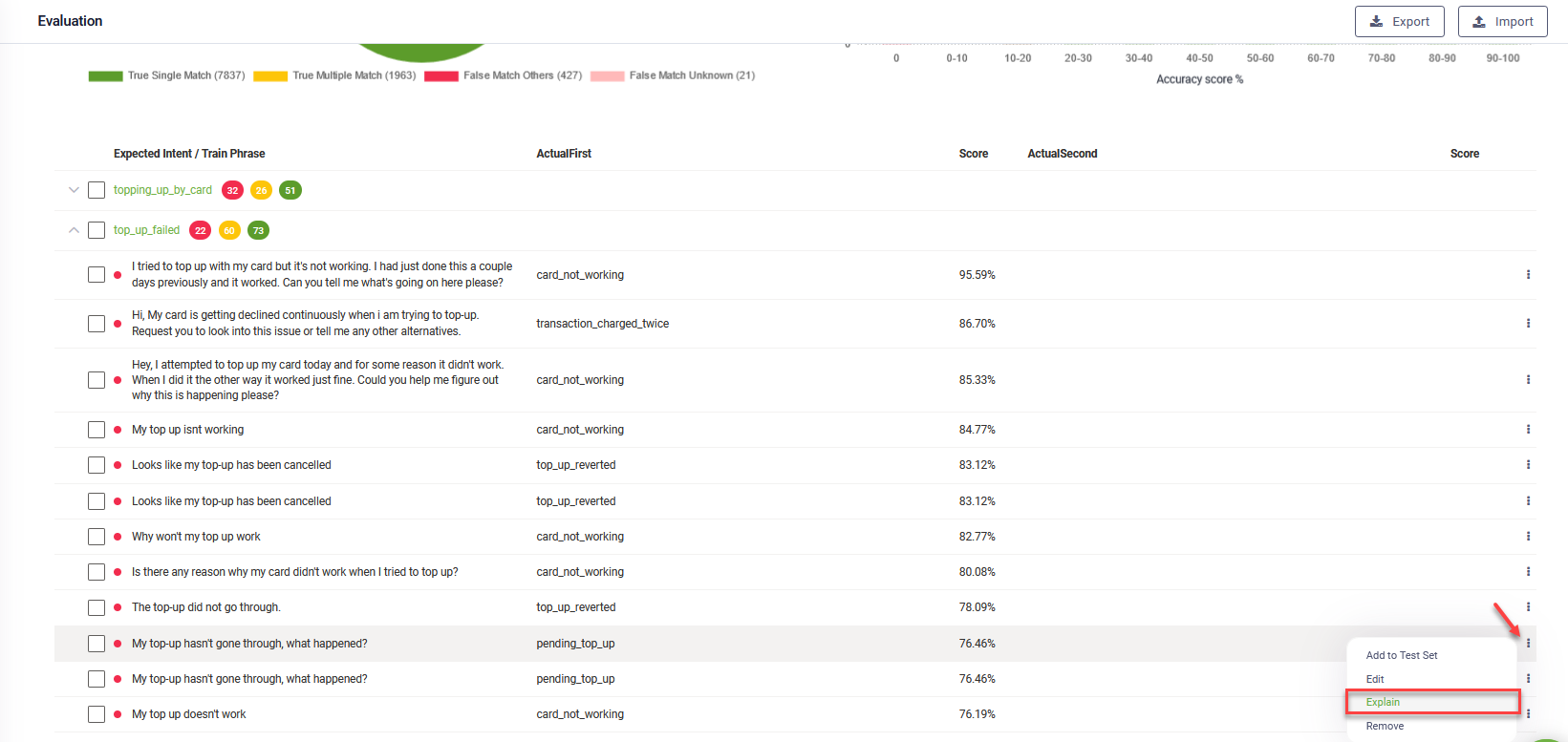
To understand why an utterance has been associated with a specific flow, click the click the  icon displayed at the right side of the utterance and click Explain.
icon displayed at the right side of the utterance and click Explain.
The explain tab provides the list of words in the flow utterance and how they contributed to the top flows association including their contribution percentage. The words that contributed positively to the flow association are marked in green and the ones that contributed negatively are marked in red.
If you decide that a flow matching is incorrect or you want to further fine tune the NLP model, you can annotate utterances by clicking the U icon at the bottom of the Explain tab.
Fine tuning the NLP model by annotating utterances
You can fine-tune the training model directly in the Explain page by making corrections to the training phrases or by deleting phrases.
Click the U icon at the bottom of the Explain tab.
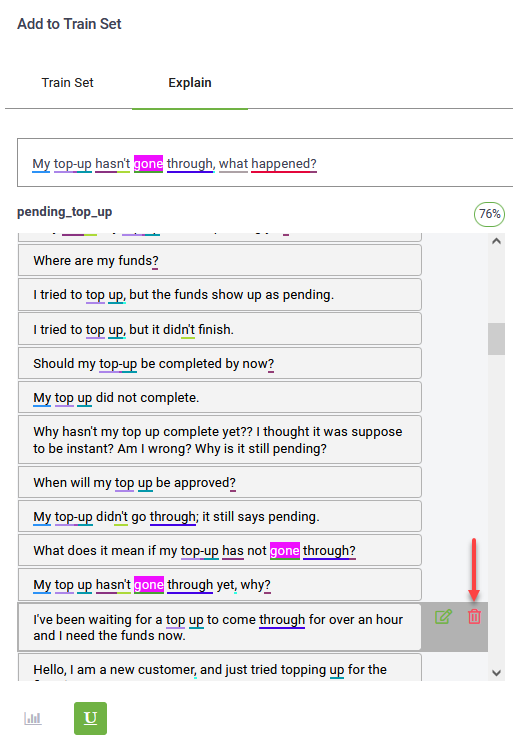
The page displays the utterances / training phrases on each top matched flow and the words from the selected training phrase marked where they appear in the training phrases on each top matched flow.
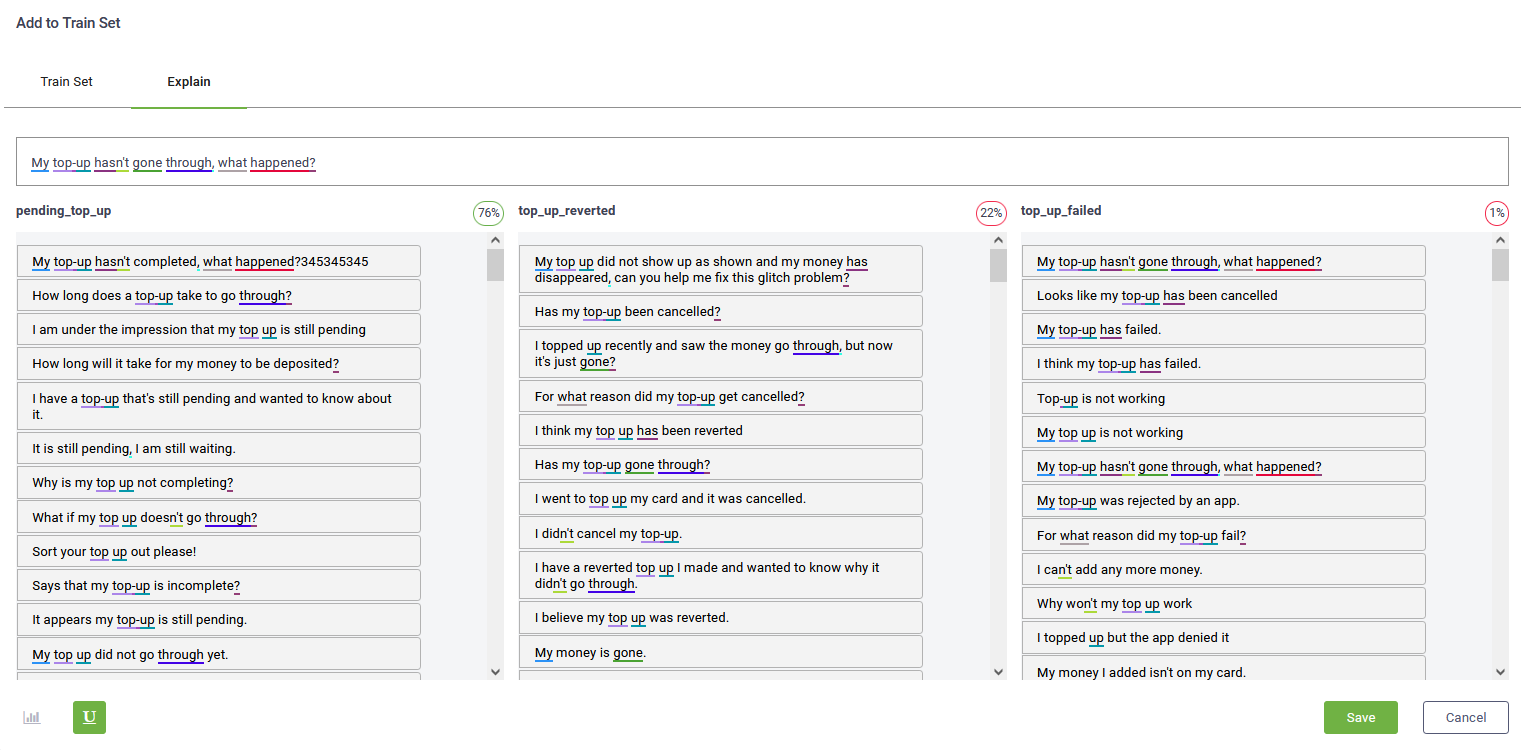
You can correct training phrases or you can delete them as best suits your needs to create a trustworthy model.
Correct training phrases
To easily spot a specific word from the training phrase, use the browser’s CTRL+F function.
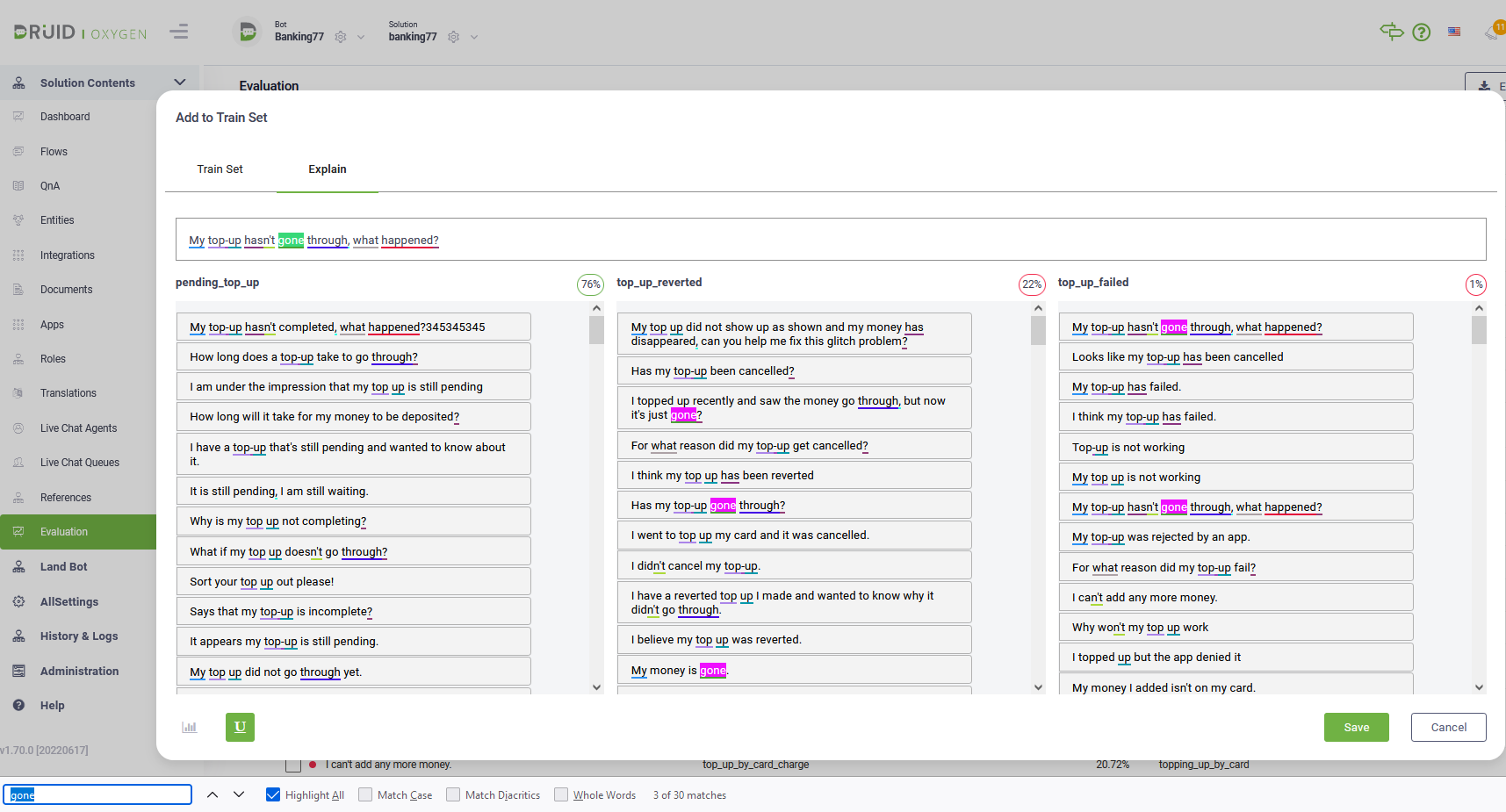
To update a specific word, hover the mouse over the phrase where you want to make the update and click the Edit icon displayed inline.
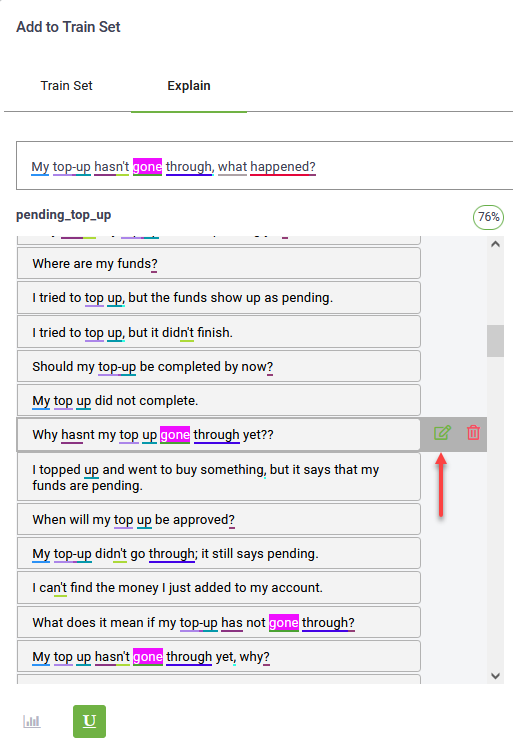
The phrase becomes editable. Change the word as best suits your needs and click the Save icon also displayed inline.
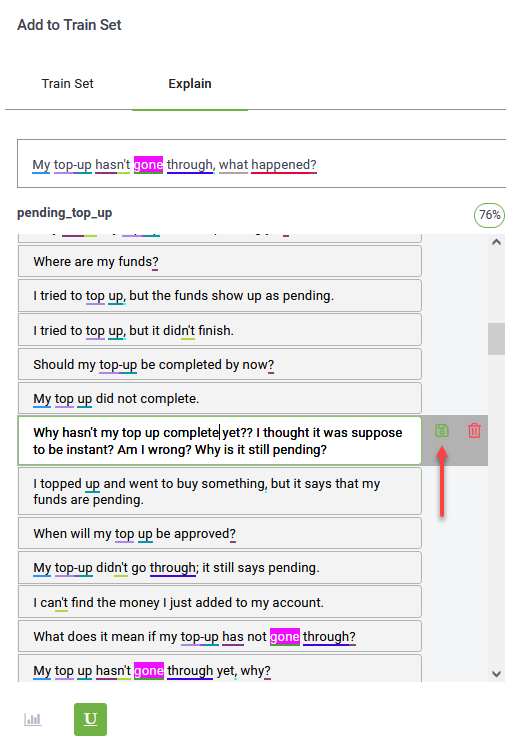
The corrected phrase becomes draft content and you need to train the bot so that the updates take effect.
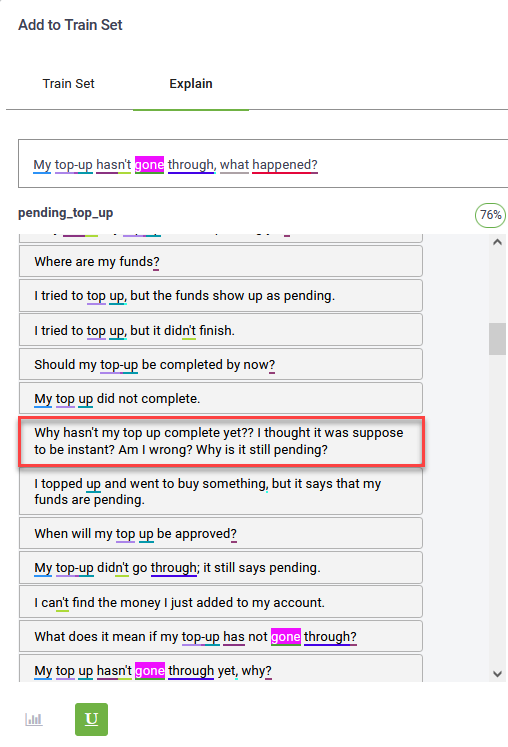
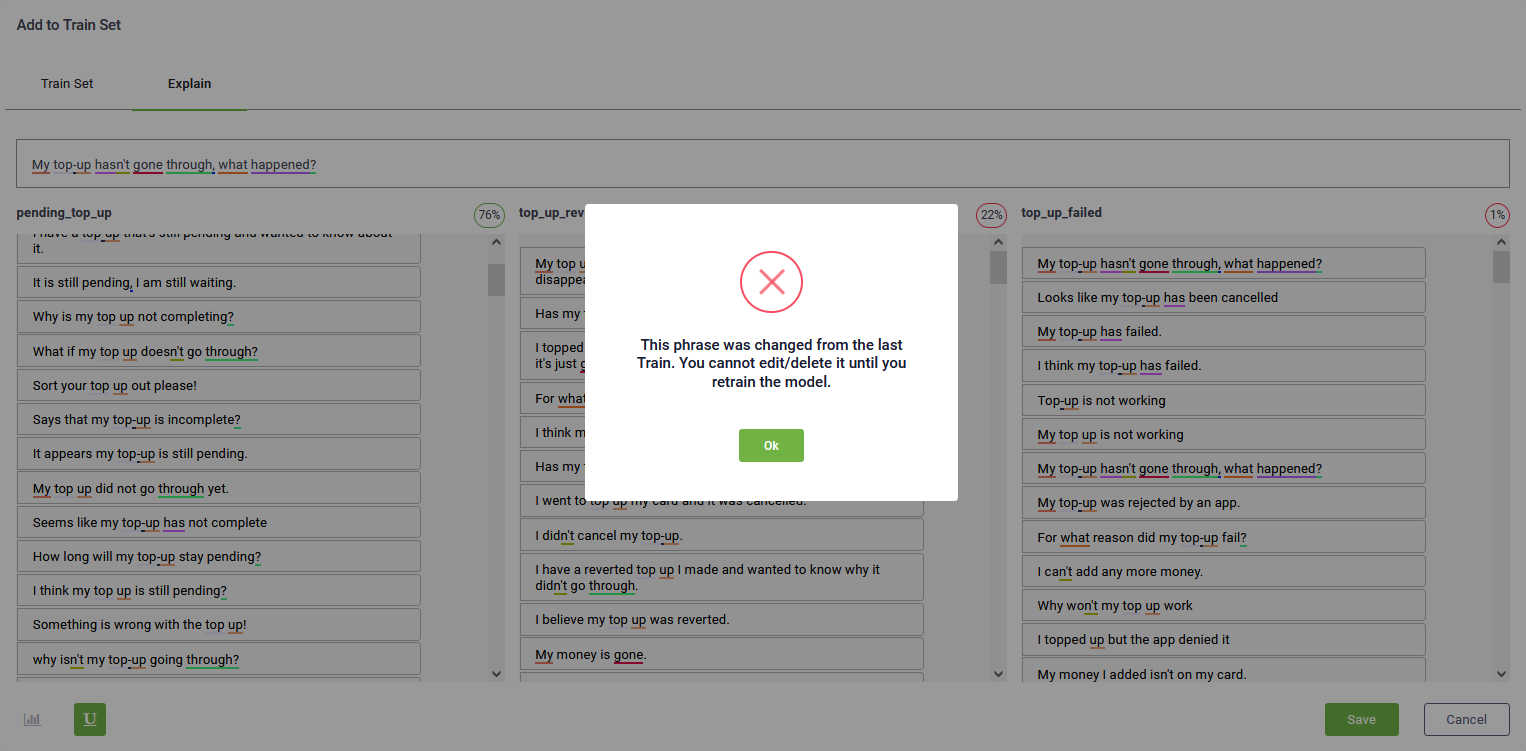
Click the Save button ( ).
).
In order for the draft content to take effect, you need to train the bot (Bot Details page > NLP section, Train button ( ).
).
Deleting training phrases
If you decide that a training phrase should be removed from the top matching flow, you can remove it. To do so, hover the mouse over the training phrase and click the Delete icon.
Click the Save button ().
The training phrase will be removed from the flow; however, in order for the update to take effect in the Evaluation tool, you need to train the bot NLP model (Bot Details page > NLP section, Train button ().